Switching to Versioned Databases
Sometimes, we are not lucky enough to start the database development from scratch. However, we can still consider switching over to the versioned database approach.
I assume that you have already read the versioned databases topic. I want to recall one part from that topic - it assumes that the database existence starts from version '0', which is the same as an un-existing state. I would like to extend on that idea in order to describe how to go from non-versioned to versioned database.
What we need to do is, change our understanding of "version 0". In case the database already exists, "0" means not an un-existing state. Instead, it means "pre-versioned" state. We simply cannot ignore the existence of the database just because we are switching to versioned mode. Otherwise, the schema that existed before versioning would be lost.
For this purpose, we need to maintain the installation script of "version 0" too. And indeed, "version 1" (as any other version) can only be installed on top of the previous version, so this step is well justified.
Since we are going to have an installation script for "version 0", obviously, it must be installed on the previous (-1) version in turn. The only thing left for scripting is to identify the non-existent (version -1) state, which is quite simple as well - either check for non-existent database, or look for one of the tables that is part of the pre-versioned (version 0) installation. The diagram below goes with the first approach in order to identify the version of the database.
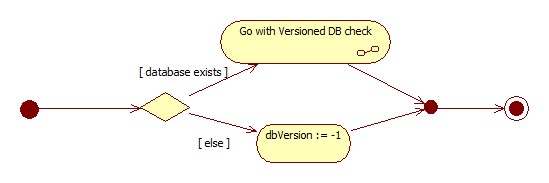
Next comes the installation of the version 0 (in case the database did not exist). That part is the same as for versioned databases, except for marking the database with the new version. The latter is not needed (and even impossible to achieve) because the version history table comes into picture with "version 1". Corresponding diagram is borrowed from the topic of the versioned databases with special note on it, asking not to mark the database with new version.
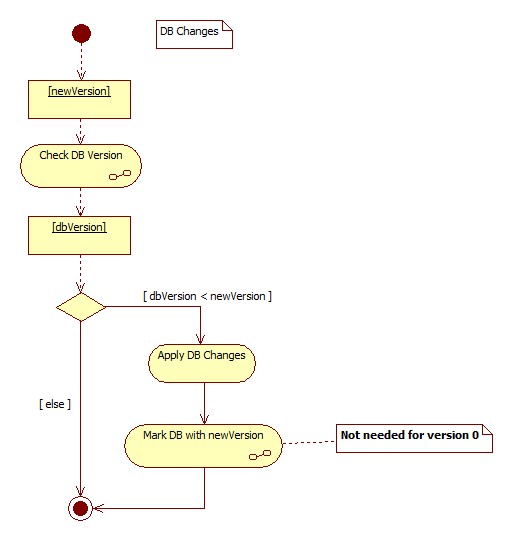
Preparing "version 0" scripts is usually done by going to the database instance and generating the scripts from it automatically. That saves us from unnecessary writing hours, as well as simplifies the switching process.
You might argue that it's convenient to store the pre-versioned scripts as part of the "version 1" installation, instead of adding one more version in front of the first version. However, that would mean the database starts existing with "version 1", not before. So, then you are not really "switching" to versioned approach, you are just starting from it (and then this whole topic does not apply).
Real Meaning of Version 0 and Version -1
Above, we went through the technical details of introducing new versions (0 and -1) to our database versioning process. Version -1 is the non-existence. Let's think about feasibility of version -1 for a moment. Will it ever happen? even if it does, is it our responsibility to rollback to version -1? is it our responsibility to start from version -1? after all, we started from pre-versioned state, which we accepted as version 0. So, why would we ever care what happened before 0?
Everything said above is true. Answer to these questions is - we need to distinguish different cases when it's relevant and when it's not:
- If we want to roll out the final version of the database on a fresh server machine, we will start from version -1 (non-existence); next, we will have to apply all our versions on top of it. Version 0 will create pre-versioned state, and the rest of the changes will be applied by the accumulative versioning system - which is the foundation of the versioned database approach. Thus, in this case, version -1 and 0 - both are relevant.
- If we are starting from the pre-versioned state, we don't have to worry about anything unusual. Our versioned scripting package will install new versions on top of it. Even if we run version 0 scripts against the existing database by accident, it won't break anything - because we have guard condition for version 0 checking whether the database exists.
- If we need to roll back to pre-versioned state, we need to be careful about running rollback scripts for all positive version numbers only (from maximum number down to version 1). However, this should already be a part of our discipline for any kind of rollback initiative - otherwise we can always rollback "too far in the past".
- I can't imagine real-life scenario when we want to uninstall version -1, but it's quite straightforward - just drop the database. Obviously, based on our previous discussions, we agreed to run all the rollback scripts in the reversed order, which is not necessary in this particular case when rolling back version -1. However, if rollback procedure is part of your automated tools or instruments (where it's easier to program running all instead of checking exceptional situations like version -1), then you could as well follow the classical approach of rolling back all versions in the reversed order. The end result will be the same.
About Author and Content
The author of the above content is Tengiz Tutisani.
If you agree with the provided thoughts and want to learn more, here are a couple of suggestions:
- Check out Tengiz's book - Effective Software Development for Enterprise. If you liked the above content, you will like this book too, because it covers similar and relevant topics.
- Consider our live, immersive technical workshop training courses around Software Architecture, Domain-Driven Design, and Extreme Programming topics, designed and delivered by Tengiz.
- Review other services to see how we could work together!.
Let's Talk