Versioned Databases
Many kinds of software depend on databases. When the software is under development, database schema often evolves from couple of tables to couple of dozens of them. Many software development teams are working under Agile processes, with many releases throughout the development road. These teams release many versions of the software, and naturally tend to produce many versions of the database as well. All these are very common scenarios in development teams.
Releasing and deploying many versions of the software is a comparably easy task - in most of the cases it's enough to replace old version of binaries with the new version of them. Few additional steps might be required (such as restarting the server machine), but those usually are of the same complexity as the software deployment itself.
On the other hand, releasing and deploying many versions of the database is a bit more challenging. With first version, you need to provide installer that creates the database and tables in their initial states. With next release, you need to transform your database in the way that it stays compatible with the newly released version of the software, and so on. Besides this primary dilemma, here are few other things that you will need to solve:
- Possible rollback of the release: you need to provide way to install the version as well as to roll it back. Rollback becomes necessary if after release, a critical issue was found, which cannot be left in production.
- Data migrations: your installation should not re-create database; instead, it should apply an increment (delta) between the previous and current release versions. This is necessary because the production database usually contains data, which should be kept with the next versions coming out.
- Build-up from zero: you should be able to install all versions till today if you lose your database server (backup mechanism is sometimes missing if data is not of any value). In another scenario, you might be rolling out a new staging environment, and need to get latest version of the database schema out there.
Principles of Versioning
Rollbacks, data migrations, and build-ups from zero lead to the common principle sitting under them - versioning of the databases. Versioning is the main instrument that I use to solve this dilemma below.
Let's agree on the definition of the version first. It is some kind of marker (label, word, number) that defines an increment (we can say which version stands before and which stands after). Version increments with every change of the software. Eventually, one of the changes makes its way to production servers, which we call a release of the particular version. The rest of the versioning principles is outside of the scope of this topic, so I am going to keep them untold.
Versioned Source Controls
Above statements fit into the nature of the versioned source controls very well, since they solve all mentioned versioning problems right out of the box, as follows:
- Rallback: can be done by rolling back the last check-in (changeset).
- Data migrations: are handled using merging features, which come with most of the modern source control systems. Every time we upgrade our local copy with the server's latest version, we migrate local changes to the new version, so that our work in progress is not lost. If no change was made locally, data migration happens automatically after we download the next available version from the server.
- Build-up from zero: happens when we get the latest version of the code for the first time. We don't need to do anything for that.
The outcome of the above said statements is that, I am treating every check-in to the source control as a new version. This is the assumption in the rest of this topic below.
Fundamentals of Versioning Databases
Versioned software is created by repeating the steps of coding and checking-in repeatedly. This can be expressed as the following diagram:
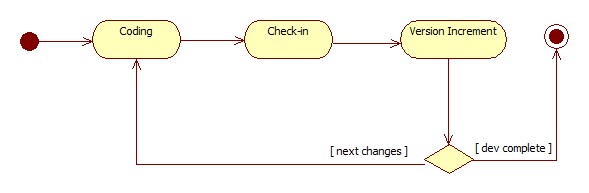
When it comes to versioning databases, we should try to keep the two versions in tact between software and its corresponding database. That means with every check-in, we need to make sure that both code and database changes are developed and committed together, so that they remain compatible with each-other. To express that, I am going to extend the software development diagram with database modification-related step:
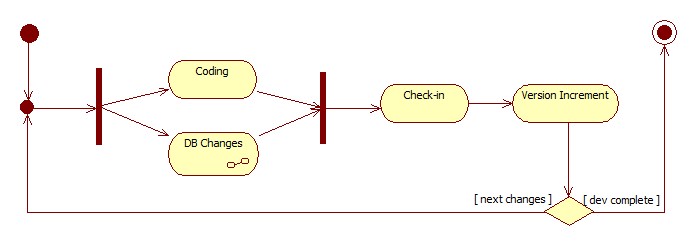
Conceptually, process of writing database upgrade script with any particular change is straightforward: we check the version of the database, and compare it to the version of the change at hand. If the version of the change stands above the version of the database (comparison is possible based on our definition of the version), then we apply new changes, and mark database with corresponding version label; otherwise, database upgrade is skipped, - since the database version is newer than the version of the change. Visually it looks as follows:
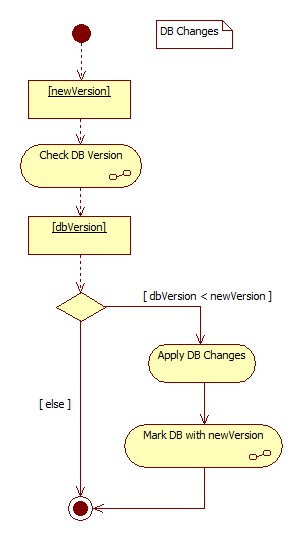
In the above diagram, we are checking the current version of the database, which is the pre-condition for applying database changes; at the end of applying changes, we mark the database with new version. In order to achieve that, we need to hold the version label somewhere in the database. One simple way is to hold it in the dedicated table, which keeps history of the database upgrades. Versioning table itself is part of the first version of changes, which means that non-existence of this table means that no version has been installed yet.
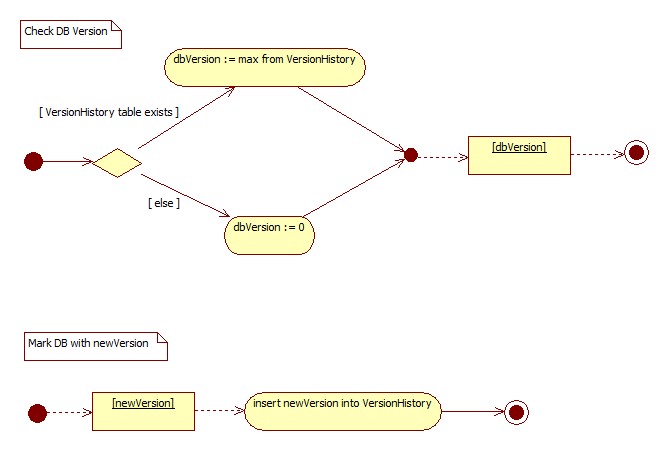
In order to check the database version, it's enough to retrieve maximum version number held by the version history table (which I called VersionHistory). If the table does not exist, database version is declared as 0.
When assigning new version to the database, we are inserting new version label into the VersionHistory table.
Based on these assumptions, I'm depicting the two procedures in the below diagrams:
Supporting Principles of Versioning
Now, let's see how the proposed solution handles versioned release tasks, such as rollback, data migrations, and build-ups from zero.
Rollback
From a high-level standpoint, rollback means opposite of the installation: check database version; if it equals to the rollback script's version, then execute the script; otherwise, skip rollback of this version.
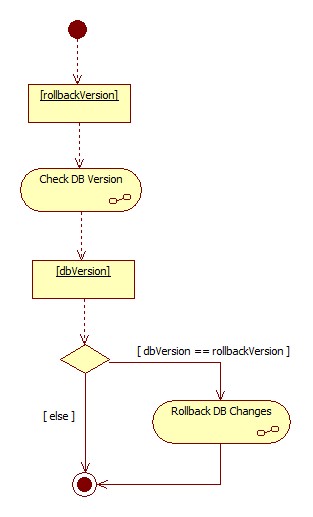
Please note that above statement creates an additional need to have rollback scripts for each version in place. Unfortunately, this is the cost you pay when you want to have versioned database.
I am skipping diagrams of the rollback script, but in short it rolls back the changes done by the corresponding installation script. This includes deletion of the version row from the VersionHistory table. For the rollback of the very first version of changes, you also need to delete (drop) the VersionHistory table. That also, naturally fits into rolling back the changes made by the installer script, since the version history table was declared as part of the first version of changes.
Data Migrations
Data migrations should be part of the install and rollback scripts as well, if applicable. Good news is that many installation scripts don't care about data migrations, unless they introduce new mandatory or calculated (derived) column, or change existing optional column into being mandatory.
Build-up from Zero
Build-up from zero is possible by running every existing version, from the very first to the latest. This works since installation/rollback scripts are accumulative, - each installation above was scripted based on the assumption that the previous version is already applied. Every rollback, in turn, was checking if the version of the database corresponds to the rollback version. So, build-up from zero seems to be possible, indeed.
By the way, for rolling back everything installed, we need to run rollback scripts in the opposite order of their version numbers, which I think you already understood.
All of the stated above proves that the proposed approach works well for solving versioning problems.
Credits
Initial inspiration to write this article reached me when I tried to use Microsoft Entity Framework Code First Migrations. That is the only framework I have used of that kind. On the other hand, implementing this approach without specialized framework was quite easy, too.
About Author and Content
The author of the above content is Tengiz Tutisani.
If you agree with the provided thoughts and want to learn more, here are a couple of suggestions:
- Check out Tengiz's book - Effective Software Development for Enterprise. If you liked the above content, you will like this book too, because it covers similar and relevant topics.
- Consider our live, immersive technical workshop training courses around Software Architecture, Domain-Driven Design, and Extreme Programming topics, designed and delivered by Tengiz.
- Review other services to see how we could work together!.
Let's Talk