Merging Versioned Databases
Merging the versioned databases is needed in number of cases. For example, teams can unite and change the ownership scope for their databases. Obviously, this would have dependency on the application ownership - thus I'm assuming that the united teams will share the ownership over their software products as well.
By merging I don't mean copying records of the two databases under the same structure. Instead, I mean a situation when we have shared physical database for versioned database schemas, and now we need to treat them as one whole database.
In this article, I will describe techniques of merging the versioned databases, since the versioned nature of them makes this move a bit tricky.
Case 1: Pre-Release State
Versioning of a database has a purpose of delivering the database changes as small increments to the production system. However, the versioned nature of the database starts existing and can evolve for quite a while before it gets to the first release cycle. So, by this we agree that the database can be versioned, and still not yet released (pre-release state).
If both databases that we are merging are in pre-release state, merging becomes somewhat straightforward and easier to accomplish: discard the versioning of one of the databases, and make it a new version of another database. It creates an effect of swallowing one database by another, and I refer to this as identifying a dominating database schema.
For example, let's consider database A, which is at version 100 at this point, and database B, which is at version 200. Let's say that we have identified A as a dominating database schema. This means, we have to add a new version (101) to A, which would contain all the existing (total of 200) increments defining B. Once the version 101 script is ready, we only have database A, and no database B anymore (A has swallowed B). Version 101 of A may be a long script, but that would represent a rather big-size delta for A, nothing more than that.
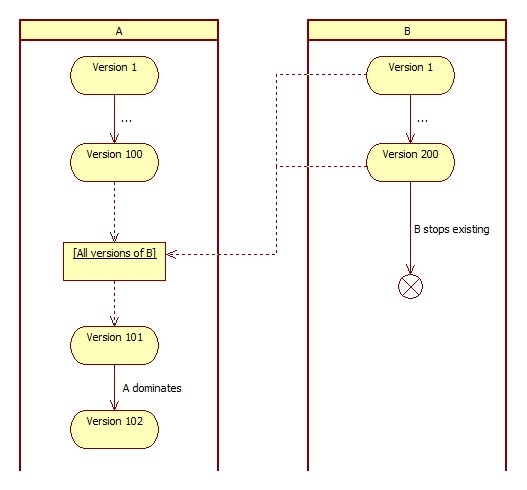
This solution also applies to the case when only one of the two databases have gone to production servers (e.g. A has been released). The only implication it has is, we need to choose the database that is not yet released as a dominator (in this example it would be B). If choice of a dominating database schema is not flexible, then read the next part of this article below, with the assumption that you treat both databases as being in the released state.
Case 2: Released State
Merging becomes a little more confusing (or clearly, harder to maintain) when both of the databases have gone to production servers. This means we have data in the database tables that we can't lose. Case 1 solution would solve this situation if not the possibility (and the need) of a rollback. If we went with Case 1 solution, we would not be able to rollback the version 101 of a dominating database A, as this would kill the database B at all - and thus lose the data.
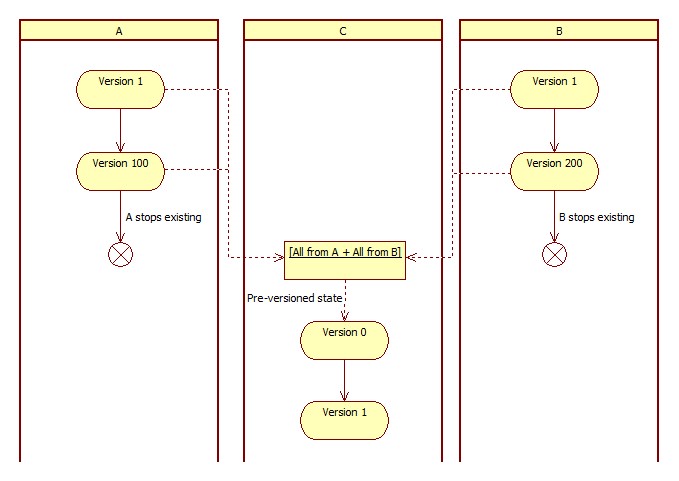
There is only one valid solution in order to still keep the versioned database approach: abandon versions of both databases, and start new versioning increments for the whole database. Treat the last versions of the both databases as a joining point of the versions, or as the pre-versioned state of the final (resulting) database.
For example, if we had database A and database B at versions 100 and 200 respectively, we would end up having database C at version 0 - pre-versioned state. Note that the merging itself does not take any specific efforts, other than declaring things in a new way (abandon A and B, introduce C). However, consecutive (upcoming) versions of C would be the only versions for the whole database schema from this point on. This creates a joint point effect for the two database versions.
If we decide to rollback the versions of the C (in the future), it would bring us to the pre-versioned C state, which is the same as A at version 100 and B at version 200. If we decide to rollback more, we need to rollback each database separately, since now (being back in time), we would have two versioned databases sharing the same physical database storage.
About Author and Content
The author of the above content is Tengiz Tutisani.
If you agree with the provided thoughts and want to learn more, here are a couple of suggestions:
- Check out Tengiz's book - Effective Software Development for Enterprise. If you liked the above content, you will like this book too, because it covers similar and relevant topics.
- Consider our live, immersive technical workshop training courses around Software Architecture, Domain-Driven Design, and Extreme Programming topics, designed and delivered by Tengiz.
- Review other services to see how we could work together!.
Let's Talk